

Definición y evolución de algoritmos de IA y redes neuronales
Historia y desarrollo
La Inteligencia Artificial (IA) se define como la simulación de procesos de inteligencia humana por parte de sistemas informáticos. Sus raíces se remontan a mediados del siglo XX: en 1943, Warren McCulloch y Walter Pitts propusieron el primer modelo de neurona artificial, precursor de las redes neuronales. En 1950, Alan Turing planteó la famosa pregunta “¿Pueden pensar las máquinas?” introduciendo el Test de Turing para evaluar inteligencia maquinal. El término “inteligencia artificial” fue acuñado en 1956 por John McCarthy, dando inicio a investigaciones que inicialmente se centraron en sistemas basados en reglas lógicas. En 1957, Frank Rosenblatt desarrolló el Perceptrón, la primera red neuronal de aprendizaje automático capaz de aprender a clasificar patrones. Durante las décadas de 1970 y 1980 la IA atravesó altibajos (los llamados «inviernos de la IA») por limitaciones computacionales y teóricas, pero en los 90 resurgió gracias al aumento de potencia de cómputo y datos disponibles.
A partir de 2010, la IA experimentó un auge acelerado con el aprendizaje profundo (deep learning), que utiliza redes neuronales de muchas capas para extraer patrones complejos. Hitos como la victoria de IBM Deep Blue sobre Kasparov en ajedrez (1997), IBM Watson ganando en Jeopardy! (2011), y AlphaGo de Google DeepMind venciendo al campeón mundial de Go (2016) ilustran progresos notables. En 2022, la compañía OpenAI lanzó ChatGPT, un modelo de lenguaje natural conversacional que popularizó la IA generativa a nivel masivo. Cada avance ha cimentado el camino desde reglas explícitas hasta sistemas capaces de aprender de datos y mejorar con la experiencia.
Principales avances recientes y tendencias futuras
En años recientes, los mayores avances provienen del aprendizaje profundo y la IA generativa. Modelos entrenados con enormes volúmenes de datos están logrando capacidades cercanas a humanas en visión, habla y lenguaje. Por ejemplo, los modelos transformers (introducidos en 2017 con Attention is All You Need) revolucionaron el Procesamiento de Lenguaje Natural al permitir entrenar modelos de lenguaje de gran tamaño (LLMs) que entienden y generan texto con coherencia. Aplicaciones como GPT-3/GPT-4 (de OpenAI) y BERT (de Google) demuestran la eficacia de arquitecturas transformer para tareas de traducción, resumen y chat conversacional. Asimismo, la IA generativa se ha extendido a imágenes (p. ej. DALL·E, Stable Diffusion) y video, creando contenido nuevo a partir de patrones aprendidos.
De cara al futuro inmediato, se espera un progreso en modelos más eficientes y especializados. Tendencias como el edge AI (IA en dispositivos locales), el entrenamiento federado (aprendizaje sin compartir datos brutos) y la IA explicable (mayor interpretabilidad de decisiones) están ganando tracción. También veremos una mayor democratización de la IA, con herramientas de código abierto y plataformas en la nube que facilitan a empresas de todos los tamaños implementar soluciones inteligentes. Los expertos anticipan que la IA seguirá evolucionando rápidamente, con mejoras continuas en capacidad de aprendizaje autónomo y en la combinación de modelos (por ejemplo, sistemas multimodales que integran visión y lenguaje). Este avance acelerado subraya la importancia de mantenerse actualizado en las últimas técnicas y de abordar implicaciones éticas conforme las máquinas asumen tareas más complejas.
2. Clasificación y principales tipos de algoritmos de IA
La IA abarca un conjunto de técnicas de aprendizaje automático (Machine Learning) que se suelen clasificar según la forma en que los algoritmos aprenden de los datos. Los tres paradigmas básicos son: aprendizaje supervisado, no supervisado y por refuerzo. Además, existen arquitecturas especializadas de redes neuronales diseñadas para distintos tipos de datos, como convolucionales, recurrentes, transformers, así como modelos generativos capaces de crear datos nuevos.
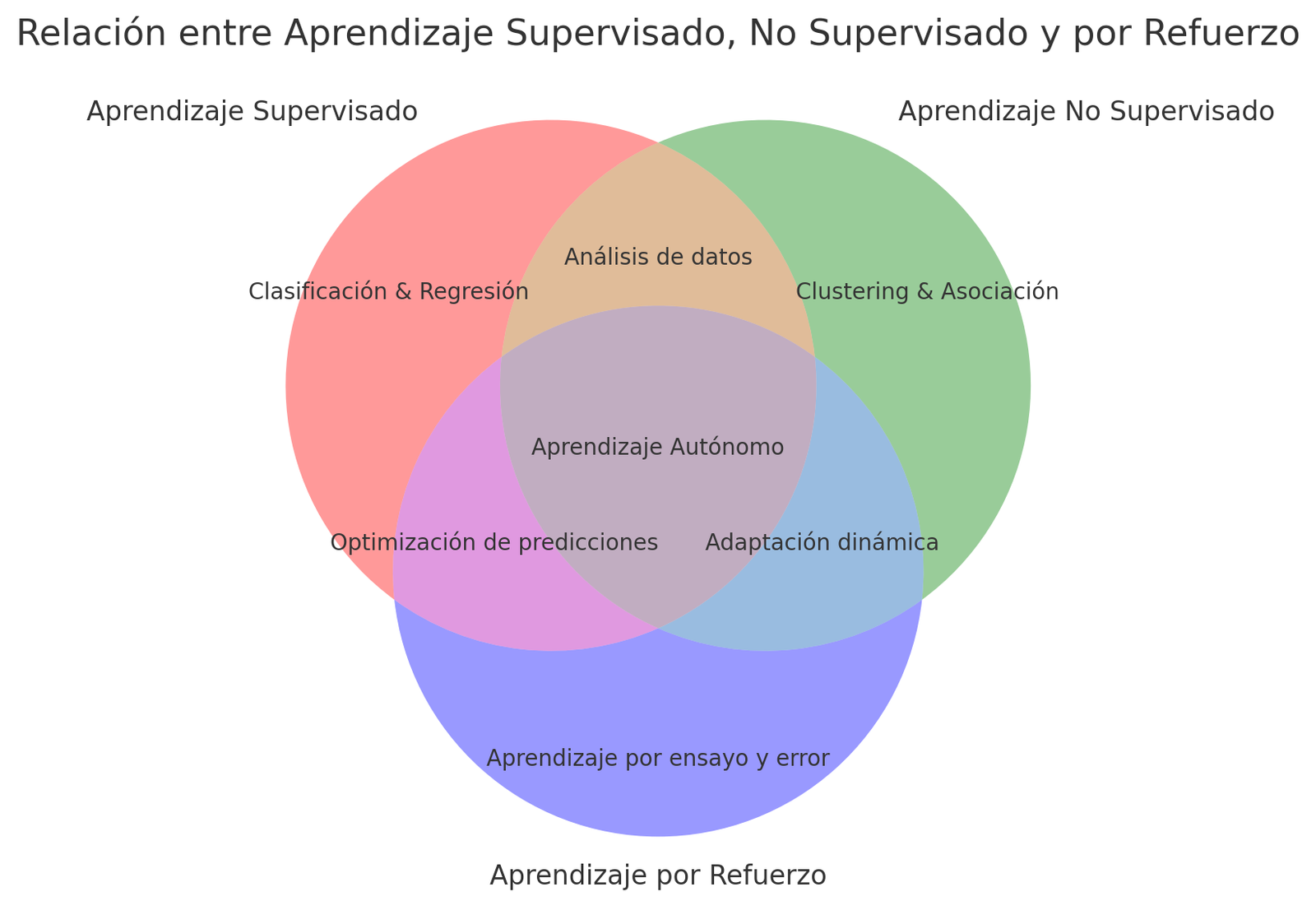
Aprendizaje supervisado, no supervisado y por refuerzo
-
Aprendizaje Supervisado: En este enfoque, el algoritmo aprende a partir de ejemplos etiquetados. Se le proporciona un conjunto de datos de entrada y las respuestas deseadas (etiquetas) para que ajuste sus parámetros y pueda predecir correctamente nuevas entradas ibm.com. Es como un tutor que corrige al modelo durante el entrenamiento. Este método es útil para tareas de clasificación (e.j., detección de spam, diagnóstico médico binario) y regresión (e.j., predicción de ventas). Algoritmos comunes incluyen árboles de decisión, máquinas de vector soporte (SVM), bosques aleatorios y redes neuronales profundas. Por ejemplo, un modelo supervisado puede aprender a reconocer imágenes de productos etiquetadas por categoría, o a predecir la probabilidad de impago de un cliente con base en su historial (modelo de riesgo crediticio). El aprendizaje supervisado logra alta precisión cuando se cuenta con gran cantidad de datos de entrenamiento etiquetados, pero esa dependencia de datos etiquetados puede ser un desafío en entornos donde obtener dichas etiquetas es costoso o lento.
-
Aprendizaje No Supervisado: En este caso, el algoritmo explora datos sin etiquetar, descubriendo patrones ocultos sin guía externa ibm.com. Se emplea para agrupar datos similares (clustering), reducir dimensionalidad (p.ej., compresión o visualización de datos) y detectar reglas de asociación. Un ejemplo clásico es el algoritmo k-means, que segmenta clientes en grupos en función de similitudes de comportamiento sin saber de antemano qué define cada grupo ibm.com. Las técnicas de clustering permiten identificar segmentos de mercado o detectar anormalidades (outliers) en transacciones financieras sin necesidad de ejemplos de fraude conocidos. El aprendizaje no supervisado es útil para descubrimiento de conocimiento, ofreciendo insight sobre la estructura de los datos. Sin embargo, interpretar los grupos o patrones resultantes requiere a veces expertise del dominio, y garantizar que los hallazgos sean accionables puede ser complejo. Aun así, en aplicaciones como segmentación de clientes, motores de recomendación (que encuentran relaciones entre productos y usuarios) y análisis exploratorio de datos masivos, este enfoque es invaluable.
-
Aprendizaje por Refuerzo: Aquí el algoritmo (agente) aprende mediante prueba y error, interaccionando con un entorno y recibiendo recompensas o castigos según sus acciones. El objetivo es descubrir una secuencia óptima de decisiones para maximizar la recompensa acumulada. Esta técnica se inspira en cómo aprenden los humanos o animales por ensayo y error. Un ejemplo típico es entrenar a un agente a jugar videojuegos o a controlar robots: inicialmente tomará acciones aleatorias, pero con el tiempo reforzará aquellas que conducen a resultados deseados. El aprendizaje por refuerzo ha logrado hitos como entrenar algoritmos que superan a campeones humanos en juegos complejos (Go, StarCraft). En entornos empresariales, se usa en sistemas de recomendación dinámicos, optimización de logística (un agente aprende la mejor ruta de reparto) o gestión automatizada de inversiones, ajustando decisiones en función de la retroalimentación del mercado. La fortaleza del RL (Reinforcement Learning) es su capacidad para descubrir estrategias óptimas en entornos complejos sin instrucciones explícitas aws.amazon.com. Requiere, no obstante, de mucha experimentación y cuidado para definir apropiadamente la función de recompensa, evitando comportamientos no deseados. Un aspecto poderoso es que soporta gratificación aplazada: el agente puede sacrificar recompensas inmediatas para lograr beneficios mayores a largo plazo. Esto habilita soluciones de IA que planifican con visión global, algo difícil de lograr con otros enfoques.
Redes neuronales: convolucionales, recurrentes, transformers y modelos generativos
Las redes neuronales artificiales son la base del aprendizaje profundo (deep learning). Son modelos inspirados en las neuronas biológicas, organizadas en capas, donde cada neurona realiza una suma ponderada de sus entradas y aplica una función de activación. Existen diferentes arquitecturas de redes adaptadas a tipos particulares de datos y problemas:
-
Redes Neuronales Convolucionales (CNN): Son especialmente efectivas para datos con estructura espacial, como imágenes o vídeo. Una CNN utiliza capas convolucionales que actúan como filtros deslizantes sobre la entrada, detectando características locales como bordes, texturas o formas. Estas redes imitan parcialmente el funcionamiento de la corteza visual humana. Típicamente constan de capas de convolución seguidas de capas de pooling (reducción de dimensionalidad), y finalmente capas densas (completamente conectadas) que realizan la clasificación o regresión. La convolución permite la invariancia espacial, es decir, reconocer un patrón sin importar su posición u orientación en la imagen. Gracias a esto, las CNN han logrado resultados sobresalientes en clasificación de imágenes, detección de objetos y reconocimiento facial. Por ejemplo, una CNN entrenada con miles de radiografías puede aprender a detectar indicios de neumonía en nuevas imágenes con precisión superior a médicos en algunos casos. Las CNN también alimentan sistemas de visión en coches autónomos y aplicaciones de inspección automatizada en fábricas. Desde el desarrollo de LeNet-5 en los 90 (reconocimiento de dígitos escritos) hasta AlexNet (ganador del concurso ImageNet 2012 que supuso el boom del deep learning), estas redes han impulsado la mayoría de los avances en visión artificial.
-
Redes Neuronales Recurrentes (RNN): Son arquitecturas diseñadas para procesar secuencias de datos (series temporales, texto, audio). A diferencia de una red tradicional feed-forward, las RNN incorporan loops que les permiten “recordar” información previa: la salida de una neurona en el tiempo t-1 influye en el procesamiento del tiempo t. Esto dota a la red de una memoria interna para captar dependencias a lo largo de la secuencia. En términos simples, una RNN analiza un elemento de la secuencia a la vez (por ejemplo, una palabra en una frase o un punto en una serie temporal) y actualiza un estado oculto que transporta información relevante del pasado. Esto es crítico para tareas de procesamiento del lenguaje natural (PLN) como modelado de lenguaje, traducción automática o análisis de sentimiento, donde el significado de una palabra depende del contexto anterior. También se aplican a pronóstico de demanda (usando históricos de ventas), detección de anomalías en series de sensores, o predicción del comportamiento de usuarios a lo largo del tiempo. Sin embargo, las RNN tradicionales tenían problemas para recordar dependencias de largo plazo debido al desvanecimiento del gradiente. Se propusieron variantes como LSTM (Long Short-Term Memory) y GRU (Gated Recurrent Unit) que incorporan puertas de control para gestionar mejor la memoria a largo plazo. Estas han sido exitosas en secuencias extensas, permitiendo por ejemplo transcribir audio a texto (reconocimiento de voz) o subtitular videos automáticamente. Aun así, entrenar RNN es más complejo y menos paralelizable que otras redes, lo cual dio paso a nuevas arquitecturas (transformers) que superan estas limitaciones.
-
Transformers: Son la arquitectura de última generación que ha revolucionado el procesamiento tanto de lenguaje como de otros tipos de secuencia. Introducidos por Vaswani et al. en 2017 bajo el lema “Attention is All You Need”, los modelos transformer abandonan la recurrencia y las convoluciones, y en su lugar emplean mecanismos de atención para procesar en paralelo todos los elementos de una secuencia. La atención permite al modelo ponderar la relevancia de diferentes partes de la entrada entre sí. En un transformer de lenguaje, por ejemplo, cada palabra puede “prestar atención” a otras palabras clave del contexto, logrando capturar dependencias de largo alcance de forma eficiente. La innovación clave es la auto-atención multi-cabezal, donde múltiples conjuntos de “cabezas” de atención aprenden diferentes relaciones (por ejemplo, capturar qué palabra es sujeto de qué verbo, o qué términos van juntos). Gracias a la paralelización, los transformers aprovechan mejor la computación moderna (GPU/TPU) y entrenan más rápido que las RNN equivalentes, a la vez que manejan contextos muy largos. Estas redes han demostrado un rendimiento sobresaliente en traducción automática, resumen de documentos, respuesta a preguntas y generación de texto coherente. GPT (Generative Pre-trained Transformer) de OpenAI es un claro ejemplo: un modelo transformer con miles de millones de parámetros, preentrenado con texto de Internet y afinado para tareas conversacionales. También existen transformers para visión (Vision Transformers) que tratan una imagen como una secuencia de patches y compiten con CNN en clasificación de imágenes. Dado su éxito, los transformers se han convertido en estándar en muchas aplicaciones de IA industrial, desde asistentes virtuales hasta sistemas de recomendación que manejan secuencias de interacciones de usuarios.
-
Modelos Generativos (GAN, VAE, etc.): Son una categoría de algoritmos diseñados no solo para reconocer patrones, sino para generar nuevos datos con las mismas características de los datos de entrenamiento. Entre ellos destacan las Redes Generativas Antagónicas (GANs), los Autoencoders Variacionales (VAEs) y los modelos autoregresivos o de difusión. Las GANs (propuestas por Ian Goodfellow en 2014) constan de dos redes neuronales que compiten entre sí: un generador que intenta producir datos sintéticos (imágenes, por ejemplo) que parezcan reales, y un discriminador que trata de distinguir entre datos reales y falsos. Durante el entrenamiento, el generador mejora para engañar al discriminador, y este último afina su capacidad de detección. Este juego minimax continúa hasta que las muestras generadas son indistinguibles de las reales para el discriminador. Las GANs han permitido crear imágenes fotorrealistas (rostros de personas inexistentes, estilos artísticos aplicados a fotos), síntesis de voz casi humana, e incluso datos sintéticos para aumentar conjuntos de datos escasos. Sus ventajas incluyen la capacidad de producir muestras de alta calidad y diversidad, controlando características específicas en GANs condicionales. No obstante, son notoriamente difíciles de entrenar: pueden sufrir colapso de modo (el generador produce variaciones muy similares) y son sensibles a ajustes de hiperparámetros. Por su parte, los VAEs combinan ideas de autoencoder y probabilidad: codifican datos de entrada a una representación latente comprimida y decodifican muestreando de esa representación para generar datos nuevos. Maximizan la probabilidad de recrear los datos originales, imponiendo que el espacio latente siga una distribución conocida (normal gaussiana). Aunque las muestras de VAEs pueden ser más borrosas que las de GANs, ofrecen un espacio latente continuo y estructurado que facilita manipular atributos de las salidas (por ejemplo, en generación de rostros, mover un punto en el espacio latente cambia gradualmente la expresión o edad). En los últimos años también han surgido los modelos de difusión y los transformers generativos (como GPT) que logran resultados impresionantes en la creación de imágenes y texto respectivamente, a partir de descripciones dadas por el usuario. En resumen, los modelos generativos abren la puerta a simular datos para pruebas, crear contenidos personalizados (p.ej., marketing que genera textos o diseños), o asistir en el descubrimiento de fármacos proponiendo estructuras químicas novedosas, entre muchas aplicaciones innovadoras.
3. Aplicaciones prácticas en empresas
Los algoritmos de IA y las redes neuronales se han convertido en herramientas transversales que están transformando numerosos sectores empresariales. A continuación, se destacan aplicaciones prácticas en marketing, finanzas, salud, logística y atención al cliente, junto con casos de éxito que ilustran su impacto:
Marketing y Ventas
La IA permite llevar la personalización del marketing a gran escala. Mediante algoritmos de machine learning, las empresas analizan datos de clientes (comportamiento de navegación, compras previas, interacciones en redes sociales) para segmentar audiencias y ofrecer recomendaciones o promociones a medida. Por ejemplo, Netflix utiliza IA para recomendar contenido: su sistema de recomendación analiza el historial de cada suscriptor y encuentra patrones para sugerir series o películas que probablemente le gustarán, manteniendo a los usuarios enganchados. Del mismo modo, Amazon emplea modelos de IA para su motor de “los clientes que compraron X también compraron Y”, generando recomendaciones de productos altamente relevantes que impulsan las ventas cruzadas. En campañas publicitarias, la IA ayuda a optimizar el gasto mediante segmentación precisa y compra programática de anuncios. Plataformas como Google Ads integran algoritmos que ajustan automáticamente las pujas en subastas publicitarias en tiempo real, aprendiendo qué combinaciones de anuncio y audiencia logran más conversiones. Un caso de éxito es Nike, que empleó IA para lanzar la campaña Nike Maker Experience, donde un sistema de visión por computador y proyección permitió a clientes diseñar zapatillas personalizadas en minutos, recopilando datos valiosos sobre preferencias de diseño. Los resultados en marketing impulsado por IA suelen ser: mayores tasas de conversión, mejora en la retención de clientes y un ROI superior gracias a interacciones más relevantes.
Finanzas
El sector financiero fue un temprano adoptante de IA debido al gran volumen de datos y la necesidad de decisiones rápidas y precisas. Una aplicación crítica es la detección de fraudes: los bancos y empresas de tarjetas de crédito entrenan modelos supervisados (p.ej., árboles de decisión, redes neuronales) con historiales de transacciones marcadas como fraudulentas o legítimas. Estos algoritmos aprenden a reconocer patrones sutiles de anomalía en tiempo real y pueden bloquear operaciones sospechosas instantáneamente Por ejemplo, si de pronto hay cargos inusuales en ubicaciones geográficas atípicas para un cliente, el sistema de IA puede denegarlos y alertar al usuario, reduciendo pérdidas por fraude. Empresas como PayPal o Visa reportan haber reducido drásticamente el fraude gracias a IA que filtra millones de transacciones por segundo con gran precisión. Otra aplicación es el trading algorítmico: fondos de inversión utilizan redes neuronales recurrentes y técnicas de aprendizaje por refuerzo para predecir movimientos del mercado y ejecutar transacciones automáticamente en bolsa en fracciones de segundo. También en finanzas personales, los bancos están implementando asistentes virtuales inteligentes (chatbots bancarios) que ayudan a los clientes con consultas sobre su saldo, recomendaciones de ahorro o incluso asesoría financiera básica. Por ejemplo, CaixaBank en España cuenta con un asistente cognitivo que atiende consultas de 4 millones de usuarios en lenguaje natural. BBVA ha desarrollado algoritmos para analizar los hábitos financieros de sus clientes y ofrecerles “planes de salud financiera” personalizados; segmenta a usuarios con perfiles similares para aconsejar, por ejemplo, cómo reducir gastos o qué productos bancarios se ajustan a sus metas. Estos usos de IA en finanzas resultan en mayor eficiencia operativa, decisiones respaldadas por datos y mejora de la experiencia del cliente, a la vez que refuerzan la seguridad y cumplimiento normativo (al poder monitorear en todo momento transacciones irregulares).
Salud
La inteligencia artificial aplicada a la medicina está salvando vidas y optimizando procesos clínicos. Un campo floreciente es el diagnóstico asistido por IA mediante análisis de imágenes médicas. Las CNN han demostrado rendimiento equiparable o superior a radiólogos en tareas como detección de cáncer en mamografías o análisis de retinas para identificar retinopatía diabética. Un caso notable es un sistema desarrollado (con participación de Google Health) capaz de detectar cáncer de mama en radiografías con menor tasa de falsos negativos y positivos que médicos expertos. Además, herramientas de IA validaron que podían reducir falsos negativos en un 9,4% en pruebas de detección de cáncer, mejorando la precisión del cribado. Otra aplicación es la predicción de resultados clínicos: por ejemplo, modelos de aprendizaje automático que, con datos demográficos y clínicos de un paciente, predicen la probabilidad de que responda a una determinada terapia (como inmunoterapia en cáncer). En hospitales, la IA optimiza la logística de operaciones y camas, pronosticando admisiones o complicaciones. También chatbots médicos o asistentes virtuales proveen orientación básica a pacientes las 24 horas, descongestionando centros de llamadas. Empresas de salud están empleando deep learning para descubrir nuevos fármacos: algoritmos generativos proponen moléculas con ciertas propiedades deseadas, acelerando la fase de diseño de medicamentos. Por ejemplo, startups de bioinfotech han usado modelos generativos para identificar posibles candidatos a fármacos en meses, algo que tradicionalmente llevaría años. Si bien la IA en salud ofrece inmensas promesas, su adopción va acompañada de rigurosos procesos de validación clínica y consideraciones éticas (privacidad de datos de pacientes, sesgos). No obstante, los casos de éxito (como la detección temprana de enfermedades o la predicción de brotes epidémicos a partir de big data) evidencian su potencial para mejorar diagnósticos, personalizar tratamientos y hacer más sostenible el sistema sanitario.
Logística y Operaciones
En logística, manufactura y operaciones industriales, la IA se ha convertido en un aliado estratégico para ganar eficiencia. Un uso común es el mantenimiento predictivo: sensores IoT en maquinaria generan datos continuamente y las redes neuronales analizan esas series temporales para anticipar fallas antes de que ocurran. De este modo, empresas de fabricación pueden programar mantenimientos antes de que una máquina se averíe, evitando tiempos muertos costosos. General Motors, por ejemplo, utiliza algoritmos de IA para monitorizar en tiempo real sus líneas de producción, logrando reducir paradas imprevistas en un porcentaje significativo. En la gestión de la cadena de suministro, modelos de pronóstico (a menudo combinando técnicas supervisadas y series temporales) ayudan a predecir la demanda de productos con alta precisión. Amazon emplea IA para anticipar qué productos necesitará en cada centro logístico, optimizando la distribución de inventario y reduciendo tiempos de envío. En transporte, las IA resuelven problemas complejos de ruteo: empresas de reparto usan algoritmos de optimización y aprendizaje por refuerzo para calcular rutas de entrega óptimas considerando tráfico, ventanas de entrega y costos, logrando ahorros en combustible y tiempo. Un ejemplo es UPS, cuyo sistema ORION con IA ahorra millones de millas recorridas anualmente ajustando rutas de camiones de reparto. En puertos y almacenes, se aplican redes neuronales de visión para clasificación automática de paquetes, control de calidad y gestión de stock (p. ej., identificación de productos defectuosos en una línea de ensamblaje). Airbus ha implementado sistemas de visión con IA para inspección automática de fuselajes, detectando imperfecciones que a simple vista costaría notar, mejorando la seguridad y calidad. Todos estos casos demuestran que la IA en operaciones produce reducción de costos, incrementa la productividad y mejora la capacidad de respuesta ante variaciones del mercado o imprevistos, otorgando a las empresas una ventaja competitiva en eficiencia.
Atención al cliente
El uso de asistentes virtuales y chatbots impulsados por IA se ha extendido enormemente en la atención al cliente. Estos agentes conversacionales, basados en modelos de PLN (Procesamiento de Lenguaje Natural), pueden entender preguntas de usuarios y proporcionar respuestas inmediatas en lenguaje natural. Muchas empresas han instaurado chatbots en sus páginas web, aplicaciones de mensajería (WhatsApp, Facebook Messenger) o call centers, para atender consultas frecuentes 24/7. Esto libera a los agentes humanos para casos más complejos y mejora la velocidad de respuesta. Por ejemplo, Banco Santander y BBVA han desplegado chatbots que ayudan con operaciones bancarias sencillas, consulta de saldo, e incluso asesoramiento financiero básico, entendiendo tanto texto escrito como comandos de voz. En el sector e-commerce, los chatbots asisten a los clientes en la navegación por catálogos, seguimiento de pedidos y resolución de incidencias de posventa, incrementando la satisfacción y reduciendo abandonos. Un caso representativo es el de Iberia (aerolínea), cuyo asistente virtual basado en IA puede gestionar cambios de reserva y proporcionar información de vuelos a miles de pasajeros simultáneamente, reduciendo la carga del call center. Además de chatbots, la IA se utiliza en Análisis de Sentimiento en redes sociales: las empresas monitorean menciones de su marca y, mediante algoritmos NLP, categorizan comentarios como positivos, negativos o neutros. Esto permite responder proactivamente a quejas en Twitter o detectar crisis de reputación incipientes. Herramientas de Voice Analytics con IA también analizan llamadas de clientes a servicios de soporte, identificando emociones (enfado, frustración) para alertar a supervisores o sugerir al agente humano acciones durante la llamada. En resumen, la IA en atención al cliente permite escala y personalización simultáneamente: cada cliente se siente atendido de forma individual y rápida, y la empresa puede manejar volúmenes enormes de interacciones sin sacrificar calidad. Casos de éxito muestran mejoras en índices de satisfacción (NPS), reducción de tiempos de resolución y menores costos operativos gracias a la automatización inteligente.
Ejemplos destacados: Empresas líderes como Amazon, Google, Microsoft y Netflix ya han integrado la IA profundamente en sus operaciones para mejorar la experiencia del cliente, optimizar procesos y generar productos innovadores. Amazon no solo usa IA en recomendaciones, sino también en robótica de almacenes y su asistente Alexa; Google aplica IA desde su motor de búsqueda hasta sus servicios de traducción; Netflix personaliza todo su catálogo y miniaturas con IA; Microsoft ha incorporado modelos GPT-4 en su asistente Office 365 Copilot. Estos casos ilustran que la IA bien implementada se traduce en eficiencia operativa, decisiones basadas en datos y nuevos niveles de personalización, impactando positivamente los resultados de negocio.
4. Tendencias globales y en mercados hispanohablantes
Adopción global de IA en empresas: crecimiento y panorama actual
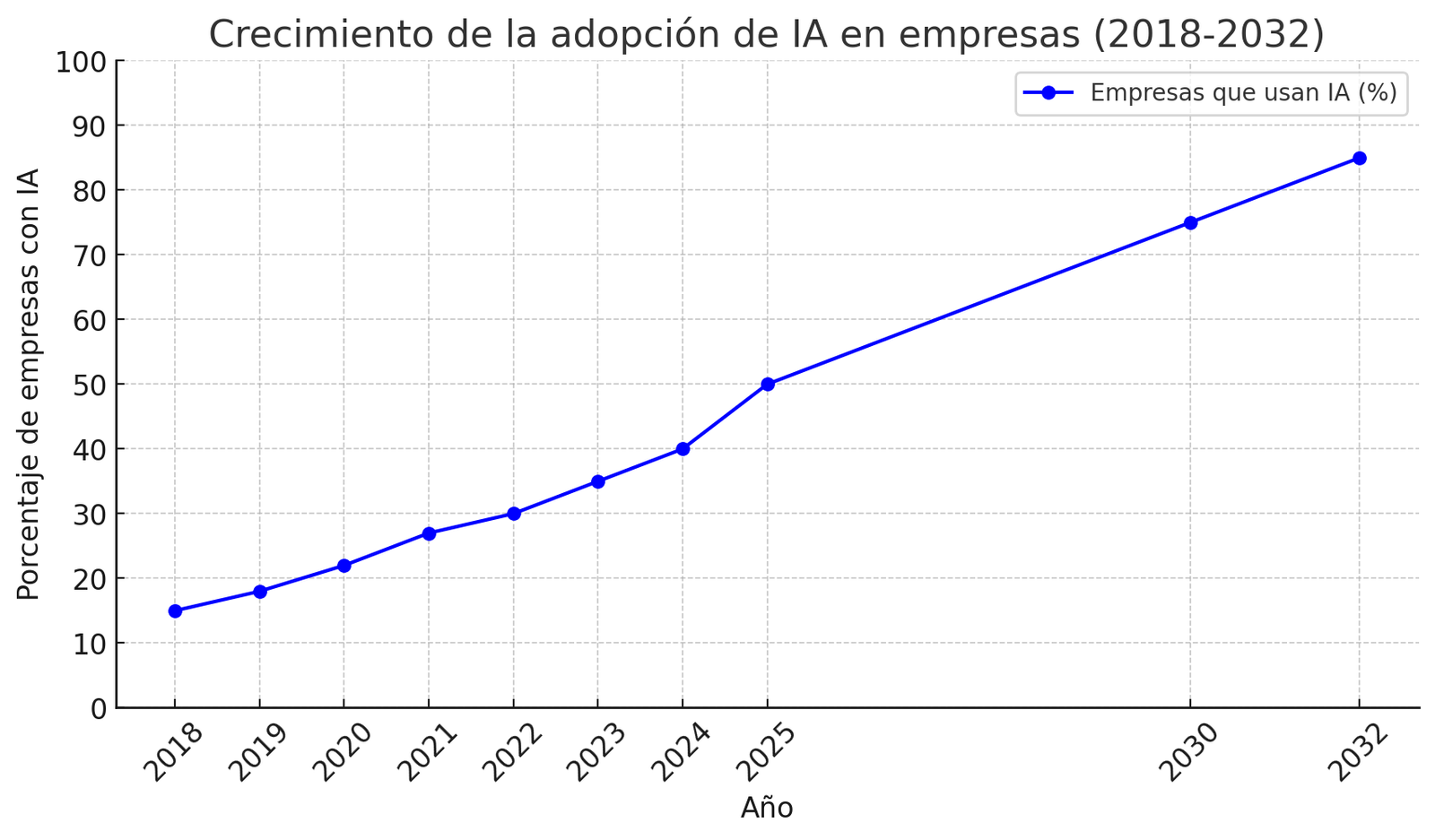
A nivel mundial, la adopción de IA por parte de las empresas se encuentra en constante crecimiento. Diversos estudios indican que alrededor de un tercio de las organizaciones ya utilizan alguna forma de IA en sus operaciones. Por ejemplo, en 2023 aproximadamente el 35% de las empresas estaban usando IA en sus negocios, lo que refleja un incremento importante respecto a años anteriores. Las industrias líderes en adopción incluyen servicios financieros, salud, comercio minorista y manufactura, sectores donde la competitividad y la abundancia de datos han impulsado la inversión en inteligencia artificial. No obstante, la implementación no es uniforme: mientras que grandes corporaciones tecnológicas poseen departamentos enteros de IA, muchas pymes aún exploran casos de uso o se encuentran en fases piloto.
A pesar del bombo mediático, la adopción real de IA empresarial se ha dado de forma gradual. Encuestas de McKinsey y otros revelan que entre 50-60% de las empresas globales han probado alguna herramienta de IA, pero la integración plena en procesos críticos aún ronda un tercio de las compañías. Eso sí, el crecimiento es sostenido: se proyecta una tasa compuesta anual de ~29% en el mercado global de IA entre 2024 y 2032. De hecho, el mercado mundial de IA, valorado en $233 mil millones en 2024, podría crecer a más de $1.7 trillones de USD hacia 2032. Este enorme salto sugiere que pasaremos de implementaciones aisladas a una amplia difusión de soluciones de IA en todas las áreas del negocio (AI everywhere). Como indicador de inversión, se estima que las inversiones globales en IA alcancen ~$200 mil millones en 2025, incluyendo gasto en software, hardware especializado (GPUs, chips AI) y servicios asociados.
Una tendencia global clara es el auge de la IA generativa desde 2023. La aparición de modelos como ChatGPT llevó a muchas empresas a experimentar con generación de contenido automatizado, asistentes de programación (codex), creación de imágenes para marketing, etc. Según un informe reciente, más de la mitad de las empresas a finales de 2023 estaban al menos explorando casos de uso de IA generativa en sus negocios. Sin embargo, la adopción generalizada aún tiene barreras: falta de talento especializado, calidad y gobernanza de datos y preocupaciones por riesgos y regulación (seguridad, ética). Las regiones difieren en ritmo de adopción: América del Norte y Asia-Pacífico suelen liderar en inversión IA, con Europa siguiendo de cerca pero poniendo mayor énfasis en aspectos regulatorios.
En síntesis, globalmente la IA está pasando de ser una tecnología emergente a una pieza central de la transformación digital. Las empresas que ya la adoptan reportan mejoras en eficiencia y capacidad analítica, mientras que aquellas rezagadas reconocen la necesidad de incorporarla para no perder competitividad. La expectativa es que en los próximos 5 años la mayoría de organizaciones medianas y grandes tengan IA integrada en múltiples funciones (finanzas, marketing, operaciones, RR.HH.), tal como Internet o la nube lo están hoy.
Escenario en mercados hispanohablantes (España y Latinoamérica)
En los países hispanohablantes, la adopción de IA sigue la estela global pero con matices locales. España, como parte de la UE, ha impulsado iniciativas nacionales de IA (por ejemplo, la Estrategia Nacional de IA, creación de la Agencia Española de Supervisión de la IA) para fomentar su desarrollo en sectores públicos y privados. Grandes empresas españolas en banca (BBVA, Santander), telecomunicaciones (Telefónica) o energía (Iberdrola) figuran entre las más avanzadas en el uso de IA a nivel mundial. De hecho, BBVA, Santander y CaixaBank fueron reconocidos entre los 50 bancos globales más innovadores en IA por el Evident AI Index en 2023, gracias a proyectos que van desde asistentes virtuales hasta análisis avanzados de datos financieros. Asimismo, startups españolas de IA están emergiendo en áreas como visión artificial, movilidad autónoma y diagnóstico médico, apoyadas por crecientes inversiones y hubs tecnológicos (Barcelona, Madrid, Valencia). A nivel de adopción, un estudio de IBM situó a España en niveles similares al promedio global en cuanto a porcentaje de empresas que usan IA de forma activa. En Latinoamérica, en los últimos dos años se ha observado una aceleración notable en la implementación de IA. Según el IBM Global AI Adoption Index, un 67% de las empresas latinoamericanas afirmó haber acelerado el uso de IA en los últimos dos años, por encima del promedio global de 59%. Esto indica un fuerte impulso reciente, posiblemente catalizado por la pandemia (que digitalizó muchos procesos) y la disponibilidad de soluciones en la nube más accesibles. Particularmente, la región muestra apertura hacia la IA generativa: alrededor del 37% de las empresas en América Latina ya están implementando herramientas de IA Generativa activamente, y otro 45% las están explorando. Este dato (casi 4 de cada 5 empresas interesadas en IA generativa) posiciona a Latam a la par de regiones más desarrolladas en cuanto a curiosidad e intención de uso de las últimas innovaciones.
Países como México, Brasil, Colombia, Chile y Argentina lideran la adopción en la región, con sectores financieros, retail y telecom siendo vanguardia. Por ejemplo, bancos en México han lanzado chatbots con IA para clientes, y en Brasil compañías de retail usan IA para gestionar inventarios masivos. Un caso destacable es Mercado Libre (Argentina), que emplea IA extensivamente en su plataforma de e-commerce para recomendaciones, detección de fraude y optimización logística, convirtiéndose en referencia regional. No obstante, también persisten retos: en muchas empresas latinoamericanas medianas falta personal capacitado en datos/IA, y la infraestructura digital es heterogénea, ralentizando proyectos avanzados. Aun así, con el abaratamiento de la computación en la nube y la proliferación de cursos de IA, se espera que la brecha se cierre.
En general, los mercados hispanohablantes presentan un alto potencial de crecimiento en IA. Las proyecciones indican que el mercado de IA en América Latina crecerá a una tasa anual superior al 20% en esta década. Las empresas que ya han invertido están obteniendo mejoras tangibles, inspirando a otras a seguir su camino. Además, gobiernos de la región (Chile, Colombia, Uruguay, entre otros) han publicado estrategias nacionales de IA, buscando impulsar la investigación, desarrollo de talento y marcos éticos para su uso. Esto evidencia que la adopción de IA no es solo moda pasajera, sino una prioridad estratégica en economías hispanohablantes, con miras a aumentar la productividad, innovación y competitividad global.
Regulaciones y normativas emergentes

El avance acelerado de la IA ha llevado a reguladores de todo el mundo a plantear marcos normativos para asegurar un desarrollo responsable. En la Unión Europea, se ha gestado el primer gran reglamento integral sobre IA: la Ley Europea de Inteligencia Artificial (AI Act). Aprobada por el Parlamento Europeo en marzo de 2024, esta ley pionera adopta un enfoque basado en niveles de riesgo: impone obligaciones más estrictas a sistemas de IA de alto riesgo (p.ej., en salud, transporte, o que puedan afectar derechos fundamentales) y prohíbe ciertos usos considerados inaceptables (como vigilancia biométrica masiva en tiempo real). El AI Act entró en vigor en 2024 pero otorgó un período transitorio; muchas disposiciones serán obligatorias a partir de 2026. Esta ley exigirá a empresas que desarrollen o implanten IA en la UE que cumplan requisitos de transparencia, seguridad, gobernanza de datos y supervisión humana, entre otros. En paralelo, la UE ya contaba con el GDPR (Reglamento General de Protección de Datos), que aunque no es específico de IA, incide en el tratamiento justo y transparente de datos personales utilizados para entrenar algoritmos. Otras normativas europeas en preparación incluyen reglas sobre responsabilidad civil de la IA, para clarificar quién responde ante daños causados por sistemas autónomos.
España, alineada con la estrategia europea, no solo participa en la definición del AI Act sino que fue elegida para albergar la sede de la Agencia Europea de Supervisión de la IA (AESIA), que se encargará de hacer cumplir estas regulaciones en el bloque. A nivel local, España ha lanzado su Carta de Derechos Digitales que incluye principios para el desarrollo ético de la IA, y planea mecanismos para certificar algoritmos en ámbitos críticos. En Iberoamérica, aunque no existe (por ahora) una regulación unificada, sí se observan esfuerzos: Argentina y México discuten leyes de protección de datos personales actualizadas para abordar datos masivos y algoritmos, y Chile reformó recientemente su Constitución para garantizar derechos de protección de datos que inciden en IA. Además, organismos internacionales como la OCDE y la UNESCO han emitido directrices éticas para la IA, adoptadas voluntariamente por numerosos países hispanohablantes, enfatizando valores de transparencia, rendición de cuentas, imparcialidad y seguridad.
En el mundo empresarial, las normativas emergentes significan que las compañías deberán adaptar sus prácticas de IA a nuevos estándares legales. Entre las implicaciones prácticas destacan: realizar evaluaciones de impacto algorítmico antes de desplegar IA de alto riesgo, documentar los datos usados para entrenar modelos (proveniencia, posibles sesgos), garantizar la posibilidad de explicación de las decisiones automatizadas y obtener consentimiento informado de usuarios cuando corresponda. Por ejemplo, si un banco usa IA para aprobar créditos, en Europa tendría que informar al cliente si una negativa fue decidida por un algoritmo y ofrecer revisión humana. También crecerá la importancia de las prácticas de IA ética corporativa: muchas empresas están formando comités internos para vigilar que sus sistemas de IA no discriminen (evitar sesgos de raza, género, etc. en modelos de contratación o crédito) y respeten la privacidad. Vemos ya que la regulación busca generar confianza en el uso de IA, evitando un “lejano oeste” tecnológico, como señaló el experto Ahmed Banafa.
En conclusión, los mercados hispanohablantes se encaminan hacia una adopción masiva pero regulada de la IA. La sinergia entre innovación y regulación será clave: normativas claras pueden dar certeza jurídica y proteger derechos, a la vez que las empresas e instituciones se benefician de la IA. Las organizaciones deberán mantenerse informadas de las leyes en desarrollo y posiblemente contar con asesoría legal/ética en IA para cumplir con los nuevos marcos. Aquellas que logren implementar IA de manera responsable y conforme a la normativa generarán mayor confianza en sus clientes y usuarios, convirtiendo la regulación en una ventaja y no en un obstáculo.
5. Comparación de herramientas y frameworks más utilizados
El ecosistema de IA y deep learning cuenta con múltiples frameworks y herramientas que facilitan el desarrollo e implementación de modelos. Entre los más populares destacan TensorFlow, PyTorch y bibliotecas del ecosistema Hugging Face, además de otros como Keras (integrado en TensorFlow), Scikit-learn (para ML tradicional), MXNet, JAX, etc. Cada herramienta tiene fortalezas y consideraciones, y la elección suele depender tanto de las necesidades técnicas del proyecto como de las preferencias del equipo de desarrollo. A continuación, comparamos brevemente los más utilizados:
-
TensorFlow: Desarrollado por Google, es uno de los frameworks de deep learning más maduros y ampliamente adoptados en la industria. TensorFlow se destaca por su robustez y escalabilidad en entornos productivos. Permite entrenar modelos en clústeres distribuidos, desplegarlos en producción (por ejemplo con TensorFlow Serving o TFX) y optimizarlos para distintos hardwares (CPU, GPU, TPU, móviles). Incorpora una API de más alto nivel llamada Keras, muy amigable para construir y entrenar redes neuronales de forma rápida. Históricamente, TensorFlow usaba un modelo de ejecución simbólica (estática) que podía ser menos intuitivo para debuggear, pero desde la versión 2.x adoptó la eager execution acercándose a la flexibilidad de PyTorch. En empresas, TensorFlow suele ser la elección para proyectos de gran escala que requieren llevar modelos a producción en servicios web o móviles, gracias a su soporte de larga data, amplia comunidad y documentación, y herramientas integrales (visualización con TensorBoard, gestión de datos, etc.). Como ejemplo, Airbnb entrenó su sistema de precios dinámicos con TensorFlow, aprovechando su capacidad para manejar grandes volúmenes de datos y luego desplegar el modelo globalmente. Ventajas: rendimiento optimizado, soporte corporativo (Google), ecosistema completo (bibliotecas para visión, NLP, etc.), portabilidad a múltiples plataformas. Desventajas: curva de aprendizaje algo pronunciada, sobre todo en versiones antiguas; puede ser verboso; la flexibilidad para investigación era menor (aunque esto ha cambiado con TF2).
-
PyTorch: Originado en Facebook (Meta AI), PyTorch ha ganado enorme tracción, especialmente en la comunidad de investigación. Su principal fortaleza es una programación dinámica y estilo “pythónico” que resulta muy natural para desarrolladores de Python. En PyTorch la construcción de la red ocurre de manera imperativa: uno puede usar estructuras de control nativas (if/for) durante el forward pass, lo que facilita depuración y experimentación. Esta flexibilidad ha hecho que muchos grupos académicos y startups lo prefieran para prototipado rápido de modelos novedosos. PyTorch también sobresale en la facilidad de uso y una curva de aprendizaje más suave para quienes ya conocen Python y bibliotecas científicas como NumPy. En años recientes, PyTorch ha mejorado en capacidades de producción: cuenta con PyTorch Lightning (framework para estructurar código), TorchServe para despliegue, y el formato TorchScript/ONNX para exportar modelos de forma serializada. Empresas como Tesla han reportado usar PyTorch para entrenamiento de sus redes de visión en el Autopilot, dado que les permitió iterar rápidamente en arquitectura. Ventajas: ideal para investigación y prototipos, comunidad muy activa (muchas publicaciones ML proporcionan código en PyTorch), integración nativa con Python, excelente para debugar. Desventajas: históricamente tenía menos soporte que TensorFlow en despliegue a dispositivos móviles o embebidos (aunque existen herramientas como PyTorch Mobile), y puede requerir algo más de trabajo manual para optimizaciones de bajo nivel. En entornos con recursos de hardware específicos (TPUs u otros), TensorFlow tuvo inicialmente más soporte, aunque PyTorch 2.0 ha introducido compilación mejorada que cierra esa brecha. En sumario, PyTorch suele ser preferido cuando se prioriza velocidad de desarrollo y flexibilidad, mientras TensorFlow puede ser elegido en proyectos donde la escalabilidad y la integración end-to-end (de investigación a producción) son cruciales. No obstante, ambas plataformas convergen cada vez más en funcionalidades.
-
Hugging Face (Transformers y ecosistema): Hugging Face no es un framework de bajo nivel como los anteriores, sino una empresa y comunidad que ofrece herramientas para facilitar el uso de modelos preentrenados, especialmente en Procesamiento de Lenguaje Natural (aunque ahora también en visión, audio, etc.). Su librería estrella, Transformers, proporciona implementaciones optimizadas de cientos de modelos de última generación (BERT, GPT, RoBERTa, T5, Vision Transformers, etc.) y permite cargarlos con una simple llamada de código. La gran ventaja de Hugging Face es que actúa como un repositorio central de modelos pre-entrenados: investigadores de Google, Facebook, OpenAI, universidades, etc., publican allí versiones abiertas de sus modelos, y la comunidad puede reutilizarlos fácilmente. Esto ahorra enormes costes de cómputo y tiempo, ya que uno no necesita entrenar un modelo de cero, sino que puede afinarlos (fine-tune) con sus propios datos en cuestión de minutos u horas para tareas específicas. Por ejemplo, una empresa de servicio al cliente puede tomar un modelo de lenguaje preentrenado en español y refinarlo con sus chats para tener un chatbot especializado. Hugging Face también ofrece datasets y herramientas como AutoTrain o Spaces (para implementar demostraciones web de modelos) que aceleran proyectos de IA. Cada vez más profesionales usan esta plataforma por la facilidad de experimentación y acceso a estado del arte. En contextos empresariales, Hugging Face es útil para probar rápidamente soluciones: por ejemplo, startups fintech han usado modelos preentrenados de HF para análisis de documentos legales, evitando desarrollar desde cero un modelo de NLP. Ventajas: enorme biblioteca de modelos listos para usar, interoperabilidad con TensorFlow/PyTorch (puedes cargar el modelo en uno u otro backend), comunidad activa compartiendo resultados, reducción de costos de entrenamiento. Desventajas: para despliegues ultra-optimizados tal vez requiera luego convertir el modelo a formatos más eficientes; algunos modelos son muy grandes y necesitan infra potente (aunque ofrecen versiones comprimidas o distiladas). En resumen, Hugging Face democratiza el acceso a la IA avanzada, haciendo que empresas sin grandes recursos de I+D puedan aprovechar los avances más recientes (traducción, resumen, detección de sentimiento, etc.) con mínimos ajustes.
-
Otras herramientas: Además de los anteriores, vale mencionar Keras, que en la actualidad es la interfaz de alto nivel dentro de TensorFlow (antes era separada). Keras simplifica mucho la construcción de redes neuronales con unas pocas líneas, lo que la hace muy apreciada para iniciación en deep learning y prototipos sencillos. Scikit-learn es el framework por excelencia para algoritmos de machine learning “clásicos” (regresiones, SVM, árboles, clustering, PCA…), ampliamente utilizado en tareas que no requieren redes profundas. Muchas veces un flujo de ciencia de datos empresarial inicia con Scikit-learn por su simplicidad y variedad de algoritmos, antes de considerar deep learning si es necesario. Jax (de Google) ha emergido como una librería interesante que combina NumPy con diferenciación automática y compilación just-in-time, atractiva para investigación avanzada en optimización y nuevos algoritmos (varios investigadores migran experimentos de PyTorch a JAX por su eficiencia en TPUs). MXNet (respaldado por Amazon) fue popular especialmente en la academia (usado en cursos de Deep Learning del profesor Mu Li y otros), y dio lugar a frameworks derivados como Apache MxNet o Gluon, aunque PyTorch le ha restado comunidad. En la industria también se usan herramientas como TensorRT (para optimizar modelos en GPUs Nvidia en producción), ONNX (formato estándar para exportar modelos entre frameworks) y plataformas de servicio en la nube (AWS SageMaker, GCP AI Platform, Azure ML Studio) que abstraen mucho del trabajo pesado de infraestructura.
Ventajas y desventajas resumidas: En general, TensorFlow es apreciado para producción a gran escala y despliegue multiplataforma, mientras PyTorch ofrece agilidad en desarrollo e investigación. Por su parte, Hugging Face brinda acceso inmediato a modelos de última generación, ideal para NLP y visión, a costa de depender de modelos ya entrenados (menos personalizables arquitectónicamente). Para una empresa, la decisión puede depender del tipo de proyecto: una startup enfocada en innovación rápida quizás elija PyTorch por la velocidad de iteración; una gran corporación integrando IA en su stack de productos podría preferir TensorFlow por sus herramientas de producción maduras. Afortunadamente, la interoperabilidad mejora cada año (por ejemplo, hoy un modelo puede entrenarse en PyTorch y luego exportarse a TensorFlow/ONNX para servirlo). Muchos equipos incluso usan ambos: prototipan en PyTorch y luego implementan la versión final en TensorFlow. Lo importante es considerar aspectos como: soporte de hardware, comunidad, facilidad de contratación de talento (¿qué se usa más en tu entorno? actualmente PyTorch domina en investigación y TensorFlow en muchos equipos industriales, aunque la brecha se acorta), y especificidades de la aplicación (por ejemplo, para redes gráficas u optimización convexa, existen librerías especializadas).
En cuanto a Herramientas de IA generativa, cabe destacar que OpenAI y Cohere ofrecen APIs comerciales para usar modelos de lenguaje o generación de imágenes sin preocuparse del framework subyacente; Hugging Face Hub aloja también espacios donde uno puede “arrastrar y soltar” un dataset y obtener un modelo finamente ajustado. Estas soluciones low-code o no-code están ganando popularidad, permitiendo a negocios con menos recursos de ingeniería sumarse a la revolución de la IA. Con todo, dominar al menos un framework principal (TF o PyTorch) sigue siendo importante para equipos de IA, ya que otorga la flexibilidad máxima para construir modelos a la medida y optimizarlos para casos de uso únicos.
6. Sección avanzada para expertos
En esta sección profundizamos en dos áreas técnicas avanzadas – los modelos Transformers y las Redes Generativas Antagónicas (GANs) – y abordamos mejores prácticas para implementar IA de forma eficiente en empresas, pensando en lectores con experiencia técnica.
Transformers: el modelo dominante en PLN (y más allá)
Los Transformers han redefinido lo que es posible en procesamiento de secuencias. A nivel técnico, un transformer está compuesto por bloques de codificador y/o decodificador, cada uno conteniendo principalmente dos sub-módulos: un mecanismo de auto-atención multi-cabezal y una red feed-forward (perceptrón multicapa) en cada posición. El truco está en la auto-atención: dada una secuencia de entrada (por ejemplo, las palabras de una oración), el modelo calcula scores de atención que determinan cuánto debe enfocarse cada palabra en todas las demás al construir su representación. Esto permite capturar de forma eficiente las dependencias a cualquier distancia – a diferencia de una RNN, donde la influencia decae con la distancia, o de una CNN, que cubriría contexto fijo con el tamaño del filtro. En un transformer, incluso palabras muy separadas en la frase pueden relacionarse directamente a través de la atención. Además, la atención multi-cabezal significa que el modelo aprende varios patrones de relación en paralelo: quizás una cabeza aprende relaciones de sujeto-objeto, otra detecta referencias anafóricas, otra corresponde partes de una oración con otra en traducción, etc. Por si fuera poco, al no requerir procesar secuencialmente, se puede paralelizar el cálculo para todos los tokens usando multiplicaciones de matrices altamente optimizadas en GPU. Esto conlleva enorme eficiencia en entrenamiento: por ejemplo, entrenar un modelo LSTM muy profundo en un gran corpus de texto tomaba meses, mientras un transformer con capacidad similar puede entrenarse en una fracción del tiempo con suficiente hardware.
El artículo de Vaswani (2017) demostró que “la atención es todo lo que necesitas”, eliminando la necesidad de recurrencia. Los resultados iniciales en traducción automática superaron récords previos. Desde entonces, se han desarrollado variantes: modelos encoder-only como BERT (excelentes para comprensión y clasificación de texto, entrenados con tareas de completar palabras faltantes), decoder-only como GPT (ideales para generación de texto dado que predicen la siguiente palabra) o encoder-decoder como T5 y la familia BART (útiles en tareas de secuencia a secuencia como traducción o resumen). Técnicamente, los transformers requieren incorporar información posicional (puesto que no procesan en orden, se agrega un encoding de posición a los vectores de embedding para que el orden influya). Y aunque brillan con datos secuenciales extensos, tienen sus propios retos: el costo de atención escala cuadráticamente con la longitud de la secuencia, por lo que manejar secuencias muy largas es costoso (aunque hay investigación activa en sparse attention y transformers eficientes).
Para un experto, comprender dónde radica el poder de los transformers permite ajustarlos mejor a problemas empresariales. Por ejemplo, transformers multimodales combinan texto e imágenes en un mismo modelo (como CLIP de OpenAI, que asocia texto e imágenes en el mismo espacio latente). Vision Transformers (ViT) adaptan la auto-atención a imágenes, fragmentándolas en parches y tratando estos como “palabras”, lo que ha logrado resultados comparables a las CNN clásicas en visión. En audio y series temporales también se están aplicando (Transformers de Tiempo). En esencia, el mecanismo de atención es muy genérico y potente para aprender representaciones de los datos.
Una consideración para implementaciones empresariales es el pre-entrenamiento: entrenar un transformer desde cero requiere cantidades masivas de datos y cómputo (por ejemplo, GPT-3 fue entrenado con cientos de miles de millones de palabras). Sin embargo, la buena noticia es que es posible pre-entrenar en un dominio específico (por ejemplo, texto médico, lenguaje legal) usando transferencia de aprendizaje. Alternativamente, usar directamente modelos preentrenados disponibles (a través de Hugging Face, etc.) y luego afinarlos a la tarea deseada es la vía más práctica. Por ejemplo, una aseguradora puede tomar un modelo transformer de lenguaje y refinarlo con sus bases de pólizas y siniestros para luego automatizar la lectura de informes o la contestación de consultas complejas de clientes. El resultado es un modelo con entendimiento del lenguaje casi humano, entrenado en semanas en lugar de años, gracias al pre-entrenamiento en conocimiento general del mundo.
En resumen, los transformers representan el estado del arte en modelado de secuencias, con amplia aplicabilidad empresarial: chatbots avanzados, sistemas de recomendación secuenciales (que tienen en cuenta el orden en que el usuario ve productos), análisis de logs y alertas en ciberseguridad (secuencias de eventos), etc. Para un experto, dominar esta arquitectura es esencial, pues seguirá siendo pilar de muchas soluciones en los próximos años, si bien con mejoras continuas en eficiencia e integración con otras técnicas.
GANs y modelos generativos avanzados
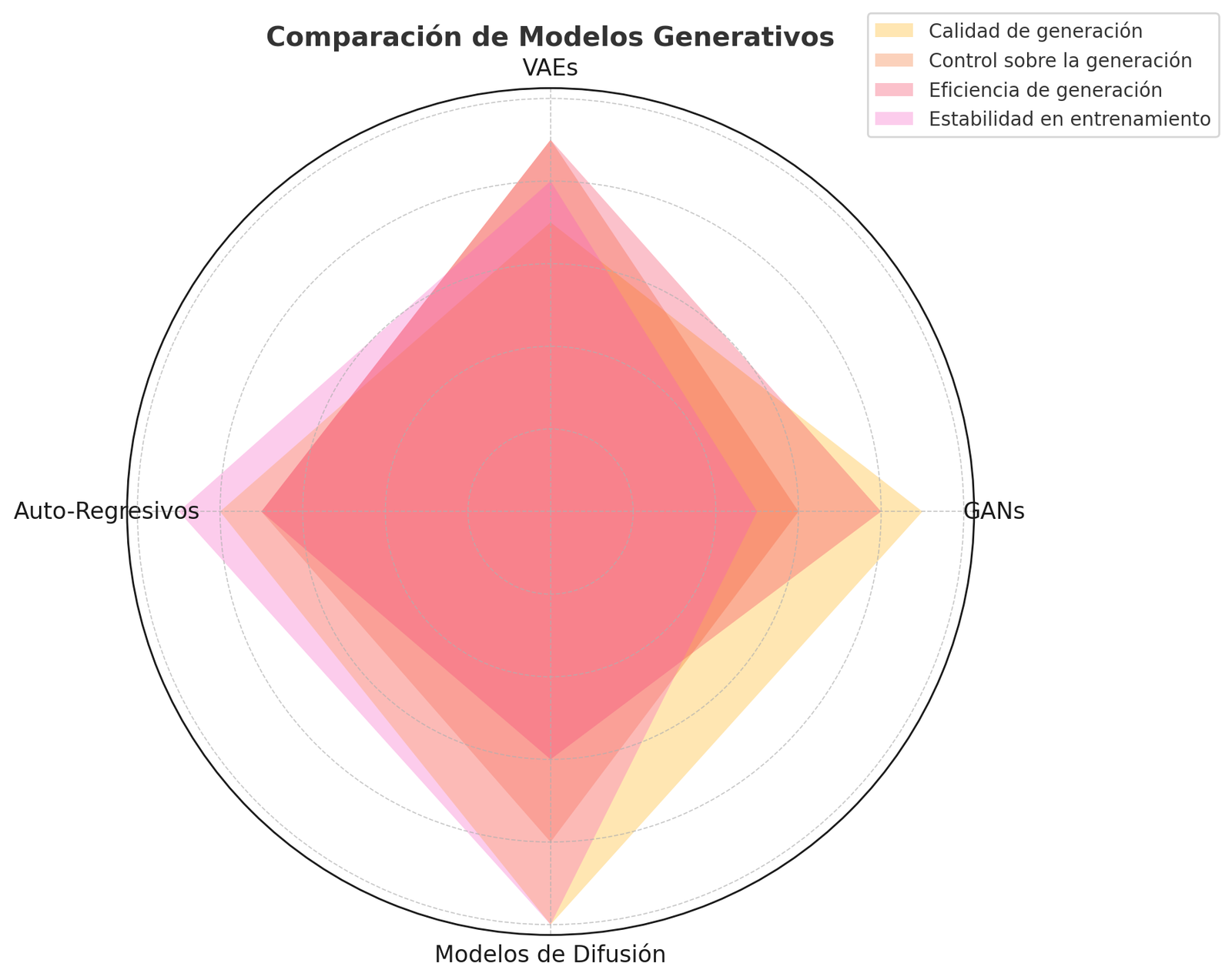
Las Redes Generativas Antagónicas (GANs), ya introducidas previamente, merecen un vistazo técnico más profundo dado su impacto en la IA generativa. Una GAN consta de dos modelos que se entrenan simultáneamente en un proceso de competencia: el generador G toma ruido aleatorio (un vector latente) y lo transforma en una muestra sintética (por ejemplo, una imagen falsa); el discriminador D recibe tanto muestras reales (del dataset) como sintéticas y debe clasificarlas correctamente como reales o falsas. La función objetivo es un juego minimax: G intenta maximizar la probabilidad de que D se equivoque (quiere producir muestras indistinguibles de las reales), mientras que D intenta minimizar ese mismo error. En términos prácticos, D entrena para asignar 1 a reales y 0 a falsas, y G entrena para que D asigne 1 a sus generadas (engañarlo). Este proceso es inestable por naturaleza; requiere un delicado equilibrio: si D es demasiado bueno, G no aprende; si G engaña demasiado fácil a D, entonces D no mejora. Por eso, entrenar GANs exige probar distintos trucos: label smoothing, batch normalization, arquitecturas adecuadas (DCGAN propuso un conjunto de buenas prácticas para GANs de imágenes), etc.
Cuando se logra el equilibrio, las GANs pueden producir resultados asombrosos. Por ejemplo, la arquitectura StyleGAN (de NVIDIA) genera rostros humanos de alta resolución prácticamente fotográficos; introduce controles en el vector latente que permiten cambiar atributos (edad, expresión, peinado) de forma continua en la imagen generada. Esto es posible porque el generador aprendió una representación latente semántica. Otra variante, CycleGAN, permite traducir imágenes de un dominio a otro sin pares alineados (por ejemplo, transformar fotos veraniegas en invernales y viceversa) – algo útil en diseño gráfico y simulación. En video, se han logrado deepfakes (sintetizar rostros en video) con GANs combinadas con técnicas de autoencoder. También se aplican en datos tabulares: GANs condicionales que generan datos sintéticos de transacciones bancarias o historiales médicos para pruebas, preservando propiedades estadísticas pero sin comprometer datos reales sensibles.
Más allá de las GANs, existen otros modelos generativos avanzados: los Auto-regresivos (como GPT en texto, o WaveNet en audio) que generan secuencia elemento por elemento condicionando en lo previo; y los Modelos de Difusión (Difussion Models), técnica reciente que ha dado un salto en generación de imágenes (ex. Stable Diffusion). Los modelos de difusión agregan ruido gaussiano progresivamente a datos de entrenamiento y aprenden a revertir ese proceso (denoising), permitiendo luego generar muestras a partir de ruido puro. Han demostrado generar imágenes con un nivel de detalle y fotorrealismo notable, compitiendo o superando a GANs, con la ventaja de mayor estabilidad de entrenamiento. Sin embargo, suelen requerir más pasos de muestreo (menos eficientes en generación rápida).
Para un experto implementando modelos generativos en empresas, las consideraciones incluyen: calidad vs. control. Las GANs producen las muestras más nítidas pero es difícil controlar exactamente qué generan sin modificaciones (aunque las GANs condicionales y StyleGAN han mejorado eso). Los modelos como VAEs ofrecen un espacio latente bien definido donde se puede hacer interpolación y aritmética vectorial (p.ej., vector «hombre con gafas» – «hombre» + «mujer» ≈ «mujer con gafas» en el espacio latente de caras), a costo de menor fidelidad. En escenarios empresariales, muchas veces se prefiere generación controlada: por ejemplo, generar variaciones de un diseño de producto cumpliendo ciertos atributos. En estos casos, se suelen usar modelos condicionales (como GANs o VAEs que reciben atributos junto al ruido). Un caso práctico: una empresa de moda puede generar imágenes sintéticas de ropa con distintas combinaciones de patrones y colores no existentes para visualizar ideas nuevas o alimentar un recomendador; aquí se entrenaría un modelo generativo condicional en base a etiquetas de estilo.
Otra dimensión es la evaluación: medir la calidad de las muestras generadas no es trivial. Métricas como FID (Frechet Inception Distance) evalúan qué tan cerca están las distribuciones de imágenes generadas vs reales en el espacio de un clasificador preentrenado (Inception). Para audio, se usan MOS (Mean Opinion Score) obtenidos por evaluadores humanos. Un experto debe tener en cuenta que la IA generativa conlleva riesgos: deepfakes pueden ser usados maliciosamente (por lo que hoy también se investiga cómo detectarlos); los datos generados podrían introducir sesgos si los originales los tenían; y hay cuestiones legales sobre propiedad intelectual (si un modelo generó algo entrenando con obra de artistas, ¿qué implicaciones tiene?).
No obstante, bien aplicada, la IA generativa es un activo poderoso. En empresas, puede significar acelerar el diseño de productos (prototipos generados por IA), crear materiales de marketing personalizados (anuncios o contenidos adaptados automáticamente a cada cliente), o simular datos para entrenar otros modelos donde los datos reales son escasos. Por ejemplo, compañías de automoción generan escenarios de manejo sintéticos (clima extremo, casos de accidente raros) para entrenar sus algoritmos de coche autónomo en situaciones que apenas tienen en vídeo real. Otras generan diálogos sintéticos para entrenar asistentes virtuales sin necesitar recopilar millones de conversaciones reales. Estas aplicaciones avanzadas requieren equipos expertos, pero ofrecen una ventaja disruptiva cuando se logran, pues habilitan posibilidades antes inimaginables.
Mejores prácticas para implementación eficiente en empresas
Implementar IA de forma efectiva en el entorno empresarial no se trata solo de elegir los algoritmos adecuados, sino de integrarlos eficientemente en los procesos de negocio. A nivel experto, esto implica considerar aspectos de ingeniería, escalabilidad, mantenimiento y alineación con objetivos estratégicos. Algunas mejores prácticas clave son:
-
Comenzar con objetivos claros y casos de uso acotados: Antes de bucear en modelos complejos, es fundamental definir qué problema de negocio se quiere resolver con IA y cómo se medirá el éxito (KPIs). Identificar quick wins – proyectos con alta probabilidad de éxito y valor tangible – ayuda a ganar tracción interna. Por ejemplo, en lugar de “queremos IA en toda la empresa”, un objetivo concreto podría ser “automatizar la clasificación de solicitudes de soporte para reducir el tiempo de respuesta en un 20%”. Para un experto, esto significa traducir la necesidad en una tarea de ML bien definida (clasificación de texto, predicción numérica, optimización, etc.) y verificar la viabilidad técnica con los datos disponibles.
-
Invertir en datos de calidad y en la infraestructura de datos: Un adagio en IA es “basura entra, basura sale”. Gran parte del éxito de un proyecto de IA radica en tener datos suficientes y depurados. Es recomendable realizar una auditoría de datos: ¿están limpios, anotados correctamente, representan todos los casos relevantes, hay sesgos? A veces es necesario dedicar tiempo a la ingeniería de datos antes de modelar: unificar fuentes, rellenar o eliminar valores faltantes, etiquetar conjuntos de entrenamiento (posiblemente con ayuda de herramientas de etiquetado o crowdsourcing). Empresas líderes en IA suelen contar con pipelines de datos automatizados para ingestión, limpieza y actualización continua de datos. Además, considerar la infraestructura: para entrenar modelos avanzados, asegurar el acceso a GPUs o TPUs ya sea on-premise o en la nube. Herramientas de big data (Spark, Data Lakes) pueden integrarse para manejar volúmenes masivos y servir de backend a los modelos.
-
Aprovechar modelos pre-entrenados y transfer learning: En lugar de reinventar la rueda, es muy eficiente partir de modelos pre-entrenados en tareas similares y luego ajustar al caso específico. Esto reduce drásticamente tiempos de desarrollo y requisitos computacionales. Por ejemplo, si se quiere un modelo para analizar comentarios en español, usar un BERT multilingüe ya entrenado y afinarlo con los comentarios propios es más efectivo que entrenar uno nuevo desde cero. Las bibliotecas y hubs modernos (Hugging Face, TensorFlow Hub, PyTorch Hub) facilitan esto enormemente. También hay APIs de servicios en la nube (Vision AI, Language AI de Google/Azure/AWS) que proveen directamente modelos entrenados; en fases iniciales pueden probarse para validar la idea antes de desarrollar una solución a medida.
-
Cuidar la división de entornos: desarrollo vs producción: En la etapa de experimentación, los científicos de datos probarán diferentes modelos, features e hiperparámetros. Pero el modelo que finalmente se implemente debe pasar por un proceso de ingeniería robusto. Es recomendable containerizar la solución (Docker), asegurarse de documentar la versión de datos con la que se entrenó (para replicabilidad), y preparar scripts de inferencia optimizados. Aquí entran en juego los principios de MLOps (Machine Learning Operations): similar al DevOps, busca automatizar y robustecer el ciclo de vida de los modelos, desde el entrenamiento hasta el despliegue y monitorización. Usar un pipeline de CI/CD que re-entrene modelos cuando haya nuevos datos o que valide que un cambio de código no degrada la precisión es deseable en entornos corporativos que escalan IA.
-
Optimización y eficiencia en producción: Un modelo que funciona bien en laboratorio puede necesitar ajustes para producción en tiempo real. Algunas técnicas avanzadas incluyen: cuantización (reducir la precisión de los pesos, e.g. de 32-bit a 8-bit, para acelerar inferencia con mínima pérdida de exactitud), podado (pruning) de redes neurales para eliminar neuronas/pesos poco significativos, y distilación de conocimiento (training de un modelo más pequeño estudiante para imitar a un modelo grande profesor). Estas técnicas pueden hacer que un modelo 5-10 veces más pequeño logre prestaciones similares, crucial si va a correr en un servidor con alta carga o en dispositivos móviles. También es recomendable utilizar formatos y runtimes optimizados: exportar el modelo a ONNX permite ejecutarlo eficientemente en distintos entornos; librerías como TFLite (para móviles) o TensorRT (para GPUs) mejoran la latencia. Un ejemplo: MobileNet es una familia de CNN diseñadas para teléfonos, con menos parámetros; un experto evaluaría si la ligera pérdida de precisión vale la enorme ganancia en velocidad para una app móvil de visión.
-
Monitorización continua y feedback: El despliegue de un modelo no es el fin, sino el comienzo de otra etapa. Es buena práctica implementar métricas de monitoreo para el desempeño del modelo en el mundo real: distribución de las predicciones, tasa de errores, detección de drift (si los datos de entrada empiezan a alejarse de lo visto en entrenamiento). Esto último es crítico: si, por ejemplo, un modelo de demanda de productos fue entrenado antes de un cambio de tendencia (digamos, surgió una moda nueva o cambio de comportamiento post-pandemia), sus predicciones podrían degradarse con el tiempo. Establecer alertas y tener un plan de re-entrenamiento periódico (o incluso learning continuo si aplica) ayudará a mantener la efectividad. Incorporar feedback humano también es valioso: sistemas semiautomáticos donde el modelo sugiere y un experto valida pueden generar un bucle para mejorar el modelo continuamente con esas correcciones.
-
Governanza, interpretabilidad y ética: Para implementaciones en empresas, sobre todo en sectores regulados (finanzas, salud, sector público), es importante poder explicar o justificar las decisiones de la IA. Técnicas de Explainable AI (XAI) como SHAP, LIME u otras pueden dar indicadores de qué variables pesaron en una predicción, lo cual es útil para auditar modelos y generar confianza en usuarios internos y externos. Además, desde el diseño se deben evaluar posibles sesgos en los algoritmos. Mejores prácticas incluyen probar el modelo en subpoblaciones (p.ej., comprobar que un clasificador de CVs no esté discriminando por género o etnia) y, de ser necesario, aplicar técnicas de mitigación de sesgo en datos o en el modelo. La ética de IA no es solo un tema de cumplimiento normativo, sino de reputación: un error de IA que cause decisiones injustas puede dañar la imagen de la empresa. Por ello, muchas compañías instauran comités de IA ética y lineamientos internos (por ejemplo, prohibiendo ciertos atributos sensibles en los datos de entrenamiento si no son relevantes).
-
Equipo multidisciplinario y formación: Implementar IA eficientemente requiere la colaboración de perfiles diversos: científicos de datos, ingenieros de ML, expertos del dominio de negocio, personal de TI, legal, etc. Las empresas exitosas crean equipos multifuncionales donde, por ejemplo, un médico colabora con un ingeniero de datos para construir un modelo de diagnóstico, o un experto en logística trabaja con un data scientist en un modelo de optimización de rutas. Esto asegura que el modelo esté alineado con la realidad operativa y se adopte en la práctica. A nivel de formación, es crucial invertir en capacitar al personal en estas tecnologías. Los expertos deben evangelizar dentro de la organización, mostrando casos de uso, enseñando conceptos básicos al equipo gerencial para que entiendan las capacidades y limitaciones de la IA, y entrenando a futuros usuarios finales en las nuevas herramientas (por ejemplo, cómo interpretar las predicciones que da el modelo).
En resumen, las mejores prácticas giran en torno a robustez, eficiencia y responsabilidad. Un proyecto de IA corporativo debe planificarse casi como un producto de software: con ciclos de desarrollo, pruebas, despliegue y mantenimiento. La diferencia es que aquí el “código” aprende y puede degradarse si cambian los datos, por lo que exige un cuidado continuo. Pero siguiendo estas pautas, las empresas pueden reducir significativamente el riesgo de proyectos fallidos y maximizar el retorno de la inversión en IA, logrando integraciones fluidas donde los modelos trabajen codo a codo con las personas en mejorar los procesos de la organización.
7. Datos y estadísticas clave
Para cerrar, presentamos datos y estadísticas recientes que ilustran el estado y tendencias de la IA en el mundo empresarial. Estos números ofrecen un panorama cuantitativo del crecimiento, adopción y proyección de la inteligencia artificial:
-
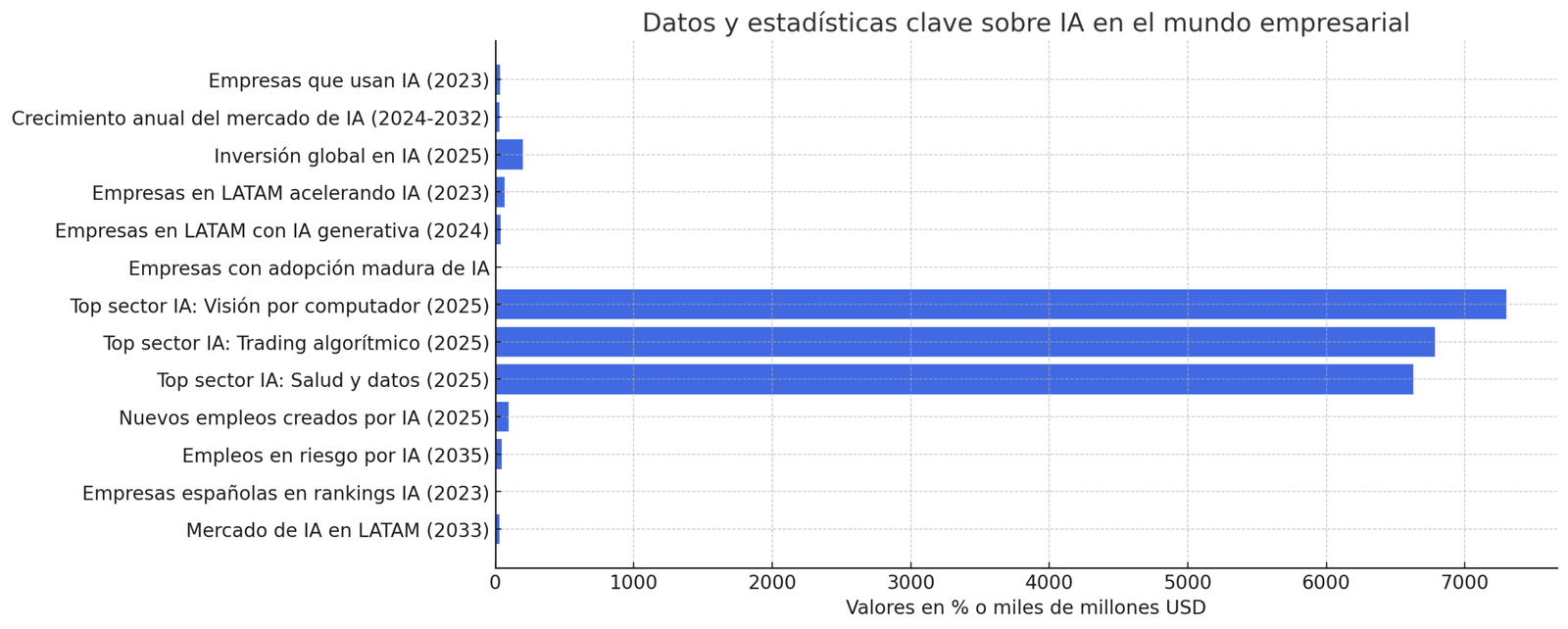
35% – Porcentaje de empresas globales que reportaron utilizar IA en 2023. La adopción ha subido desde ~20% en 2018 a un tercio en 2023, mostrando la rápida incursión de estas tecnologías en el tejido empresarial.
-
29,2% – Tasa de crecimiento anual compuesto (CAGR) proyectada del mercado global de IA entre 2024 y 2032. El mercado, valorado en $233 mil millones en 2024, podría alcanzar alrededor de $1,77 billones USD en 2032, reflejando inversiones masivas continuas en software, hardware y servicios de IA.
-
200 mil millones USD – Nivel aproximado de inversiones globales anuales en IA previsto para 2025, según Goldman Sachs. Los gobiernos y empresas están aumentando sustancialmente los fondos destinados a I+D en IA, infraestructuras y adopción de soluciones inteligentes.
-
67% – Porcentaje de empresas en Latinoamérica que indican que la adopción de IA se aceleró en sus operaciones en los últimos dos años (hasta 2023). Denota que más de dos tercios han impulsado más proyectos de IA recientemente, superando incluso la tasa global (59%).
-
37% – Proporción de empresas latinoamericanas que ya implementan IA generativa (chatbots avanzados, generación de contenido, etc.) a inicios de 2024. Adicionalmente, 45% la están explorando, lo que significa que en total ~82% de las firmas en la región muestran interés activo en IA generativa.
-
1 de cada 10 – Solo el 10% de las organizaciones aproximadamente ha alcanzado una adopción madura y amplia de IA en sus procesos (integrándola en múltiples funciones de manera transversal). La mayoría se halla en fases parciales o experimentales, indicando un gran margen de crecimiento futuro.
-
Top 3 sectores en IA (ingresos) – En 2025, se estima que las aplicaciones de IA con mayores ingresos globales serán: Visión por computador (reconocimiento/clasificación de imágenes) con ~7.300 millones de € anuales, Trading algorítmico financiero (~6.786 millones €) y Procesamiento de datos de pacientes en salud (~6.630 millones €). Otras áreas destacadas serán mantenimiento predictivo, vehículos autónomos y automatización de atención al cliente.
-
97 millones – Número de nuevos empleos que la IA podría crear a nivel mundial para 2025, de acuerdo al Foro Económico Mundial. Si bien se estima que ~85 millones de puestos actuales pueden ser desplazados por la automatización, surgirán más roles asociados a IA (científicos de datos, ingenieros de ML, especialistas en ética de IA, etc.), resultando en un neto positivo de empleos generados por la transformación digital.
-
46% – Porcentaje de empleos globales en riesgo de automatización parcial o total debido a IA en la próxima década, según la OCDE. Esto no implica desaparición absoluta, sino cambios en las tareas; enfatiza la necesidad de re-entrenar la fuerza laboral y adaptar las habilidades a la colaboración con sistemas inteligentes.
-
4 – Número de compañías españolas (BBVA, Santander, CaixaBank y Telefónica) que aparecen en rankings globales top 100 de empresas líderes en IA en 2023. Refleja la presencia de actores hispanohablantes destacados en la carrera tecnológica global.
-
$30,2 mil millones – Tamaño estimado del mercado de IA en América Latina para 2033, con un crecimiento anual del 22,9% entre 2025 y 2033. Esto indica que la región, si bien más pequeña que otros mercados, tendrá un dinamismo significativo en la adopción de IA.
(Nota: las cifras anteriores deben interpretarse en contexto; las definiciones de «usar IA» pueden variar entre encuestas, y las proyecciones de mercado asumen condiciones actuales de inversión. Aun así, la tendencia general apunta a una aceleración en la implantación de IA y un impacto cada vez mayor en la economía.)
Referencias: Este informe se basó en fuentes confiables, incluyendo publicaciones académicas, informes de la industria y casos de estudio de empresas. Se citan extractos relevantes siguiendo el formato indicado, por ejemplo corresponde a la fuente 22, líneas 25-34. A continuación se enumeran algunas de las fuentes destacadas empleadas:
- Historia y definiciones de IA: Iberdrola Innovación (Historia de la IA), McCarthy et al.
- Tipos de aprendizaje: IBM Knowledge Center (Supervised/Unsupervised) ibm.com, AWS Blog (Reinforcement Learning).
- Arquitecturas de redes: Glosario HPE (CNN), IBM (RNN), IBM (Transformers), QuestionPro (Modelos Generativos).
- Casos de uso empresariales: Revista ADEN Business (Casos de éxito IA) aden.org, Funds Society (Bancos e IA) fundssociety.com, entre otros.
- Estadísticas y tendencias: IBM AI Adoption Index eleconomista.com.mx, WEF Future of Jobs 2020 es.wired.com, Fortune Business Insights fortunebusinessinsights.com, Statista/Tractica aden.org, Punto Medio (dato 35%) puntomedio.mx, entre otras.



